Amazon Health Services
Project: Lifestyle Image Tool (LIT)
Roles: Lead Design Technologist
Year: 2025
Description: Concept and development of an AI application for the generation and modification of lifestyle images used in large-scale healthcare marketing experiments.
Problem Statement
Marketing managers for Amazon Health Services (AHS) needed to conduct high-volume, data-driven marketing experiments quickly. Their workflow from creative brief, production and creative review took two to four weeks. Optimizing the workflow required a creative and easy solution to enable marketing managers to produce and modify high-quality lifestyle images.
Ideation and Design
The ideation and design process started by talking to the end users and understanding their goals. We considered leveraging existing design tools from Figma, Adobe and others but that approach required training, time, security approvals and was ultimately less cost-effective. Once the stakeholders and I aligned on prototype I worked backwards from their goals and requirements to determine the technical stack. I began to document the workflows, acquire use cases and draft engineering designs.
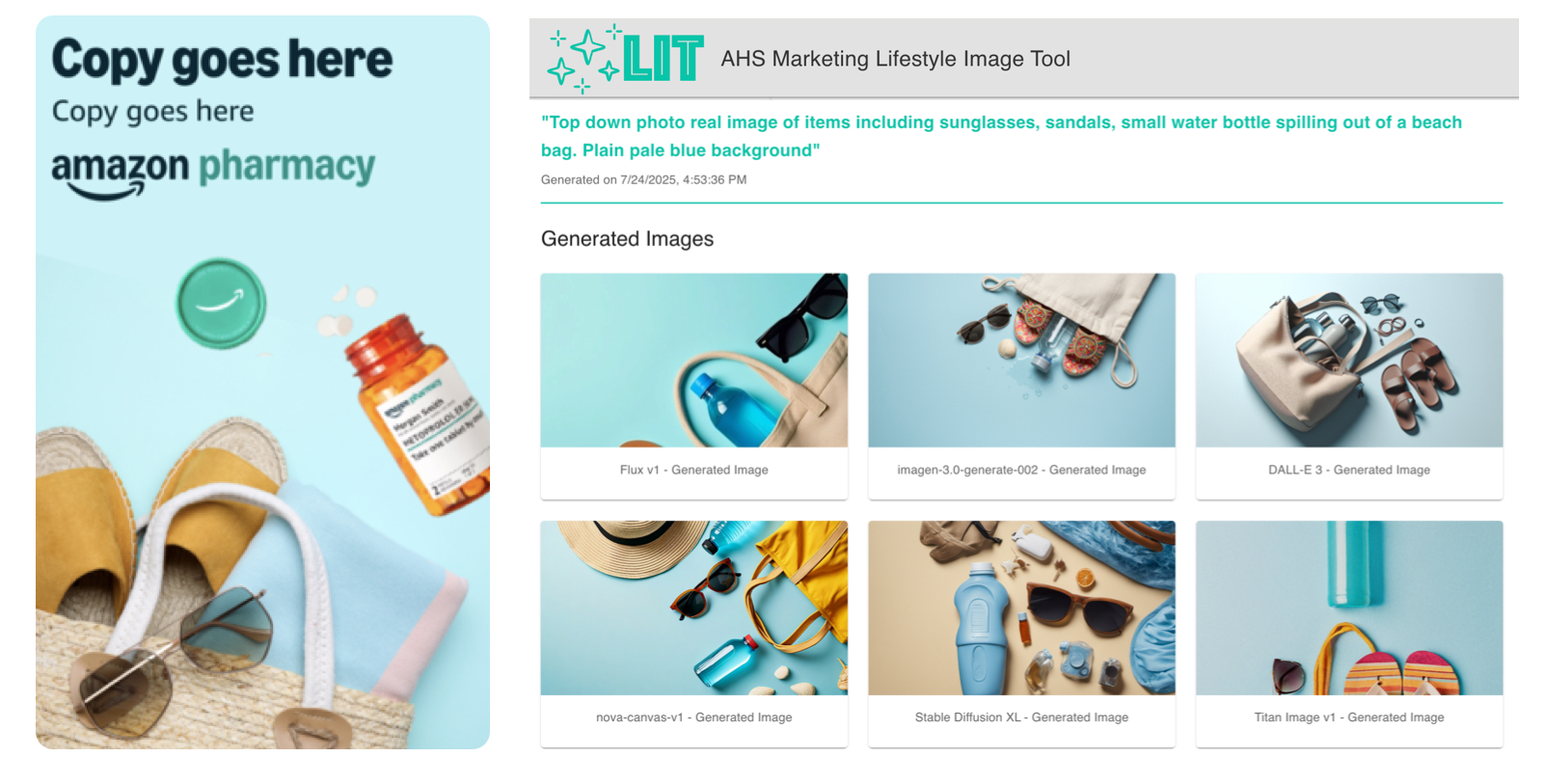
Goal 1: Produce multiple lifestyle images that match the style and tone of our studio and stock photography
Idea: Use text-to-image and text-image-to-image prompts to generate images from multiple instructed models in parallel
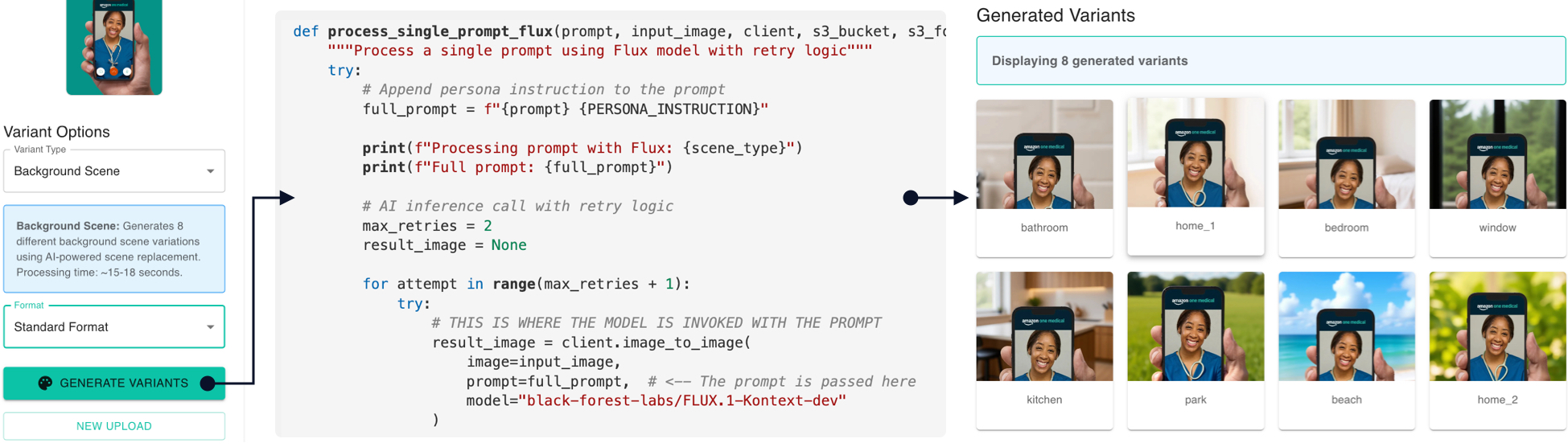
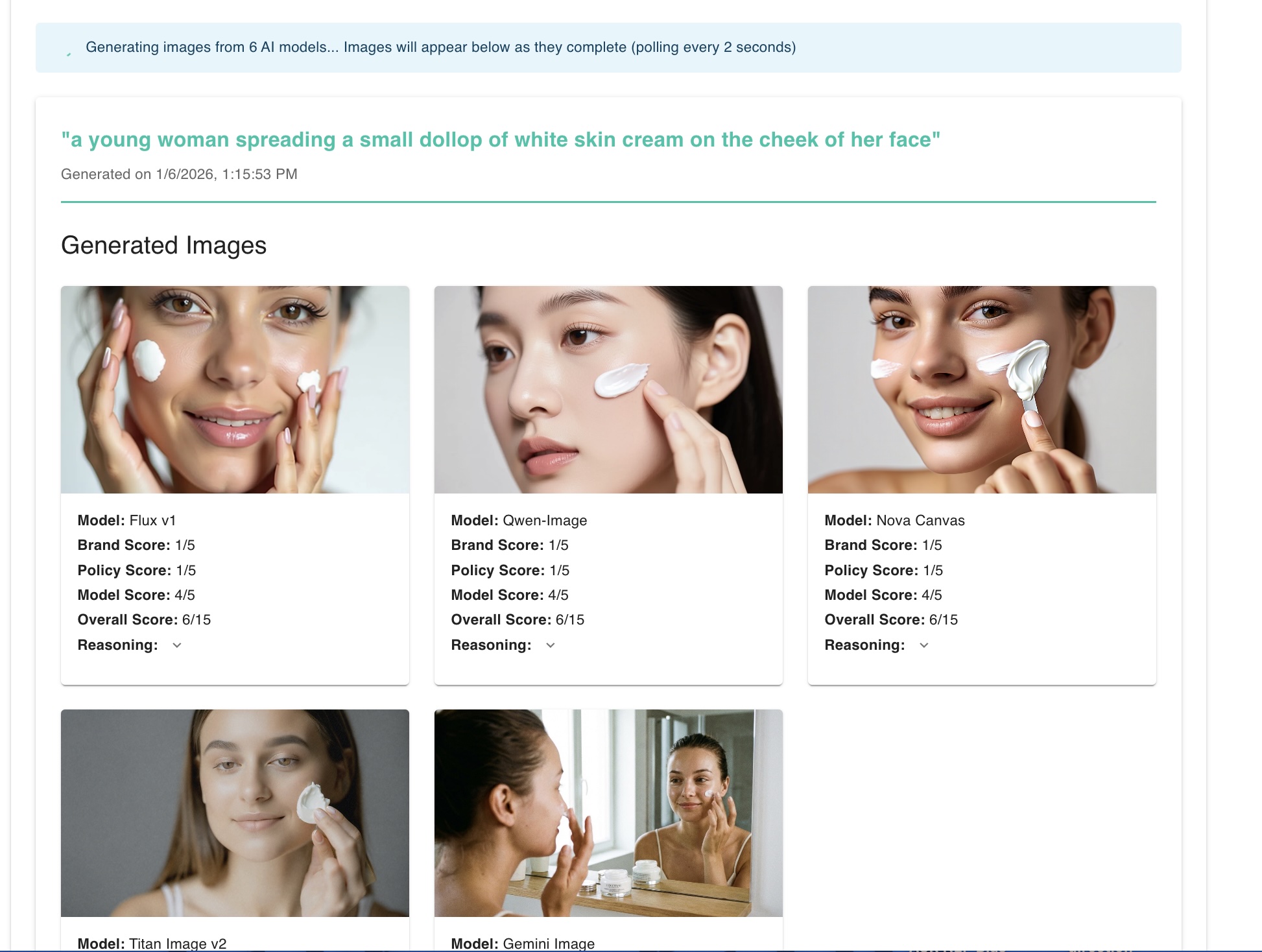
For creative image generation we look for variety in generative models, just like a brand team would look for variety in photographers. Some models respond to certain prompts better than others. By showing six or more model responses we enable the type of choice expected in the creative production process.
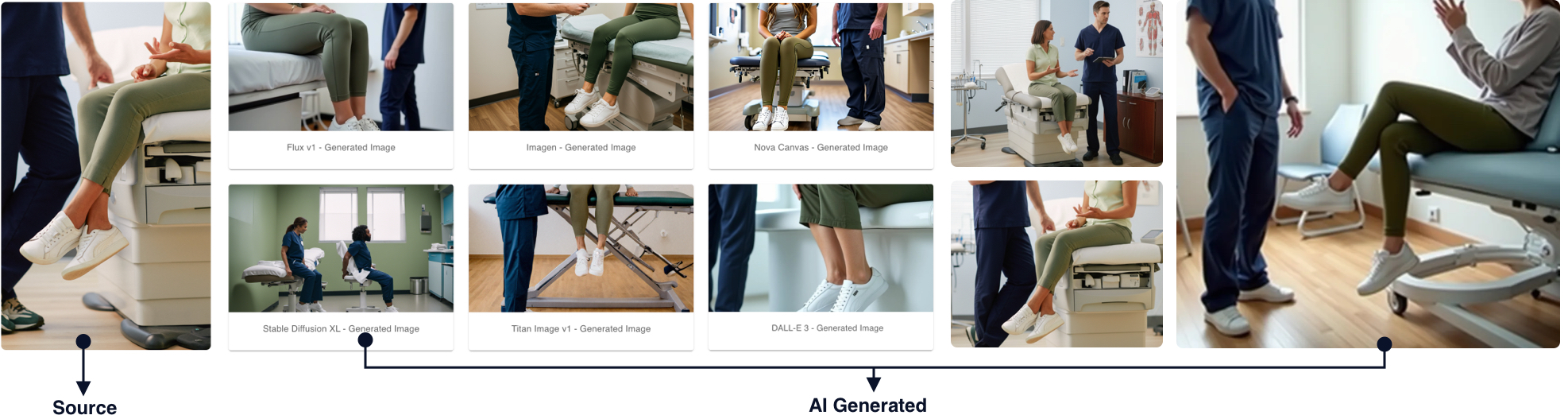
Goal 2: Enable modification of existing lifestyle images that are already pre-approved for marketing
Idea: Manual and automatic image inpainting from structured prompts with brand guidelines as context

Some existing images were well suited for background replacement. By leveraging the primary and secondary brand color palettes we would be able to exponentially scale the number of new images that could be used for experimentation.
High-quality image modification often requires detailed system instructions behind the scenes. Because end-users may not have the knowledge or ability to do this, our prototype could abstract this process and present a range of subtle variants for them to choose from.
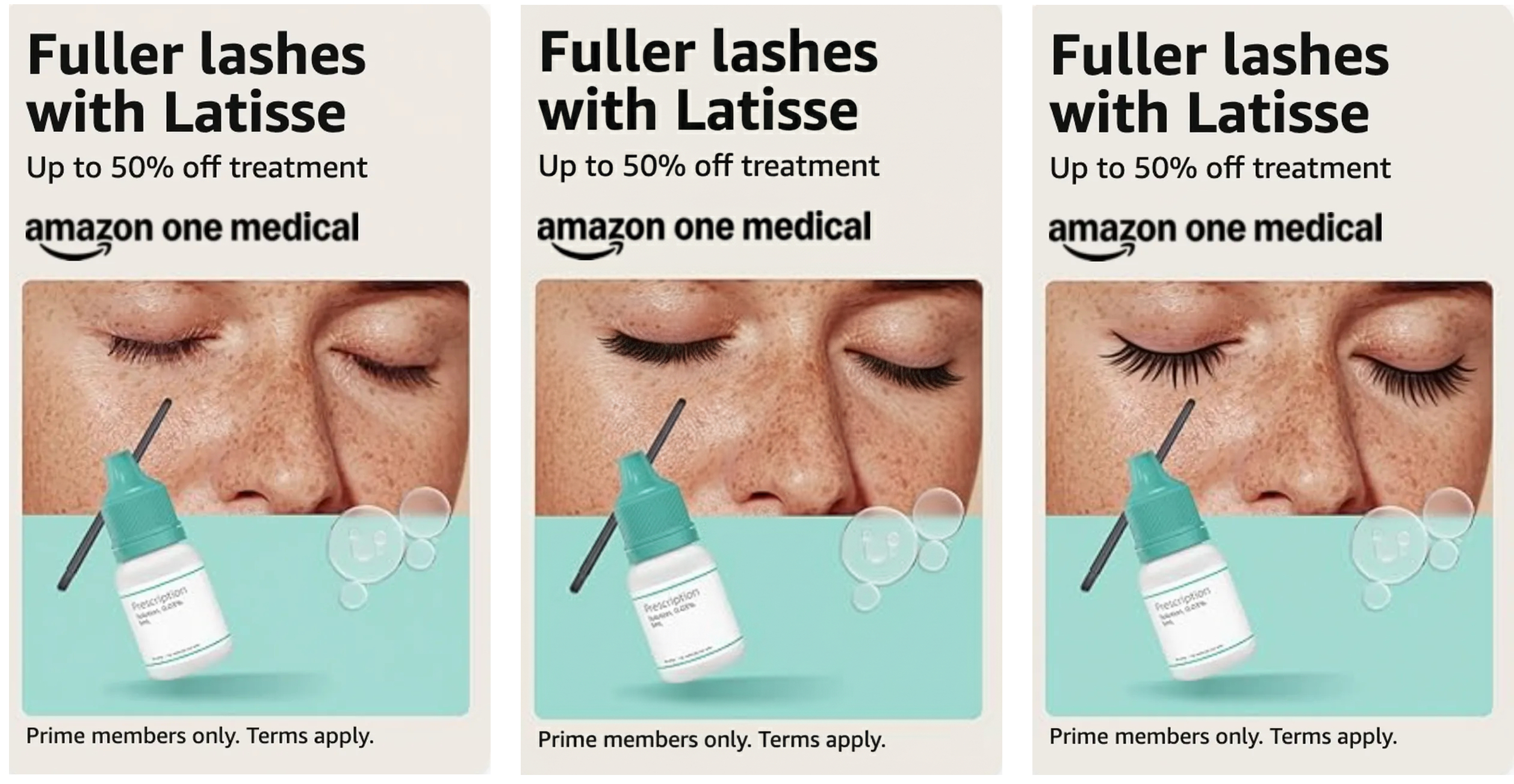
Goal 3: Optimize the production and review process for AI generated lifestyle images
Idea 1: Generate quality, brand and policy compliance scores based on real-time LLM evaluations to speed up reviews
Idea 2: Include basic editing tools for end-users who lacked training or access to design programs
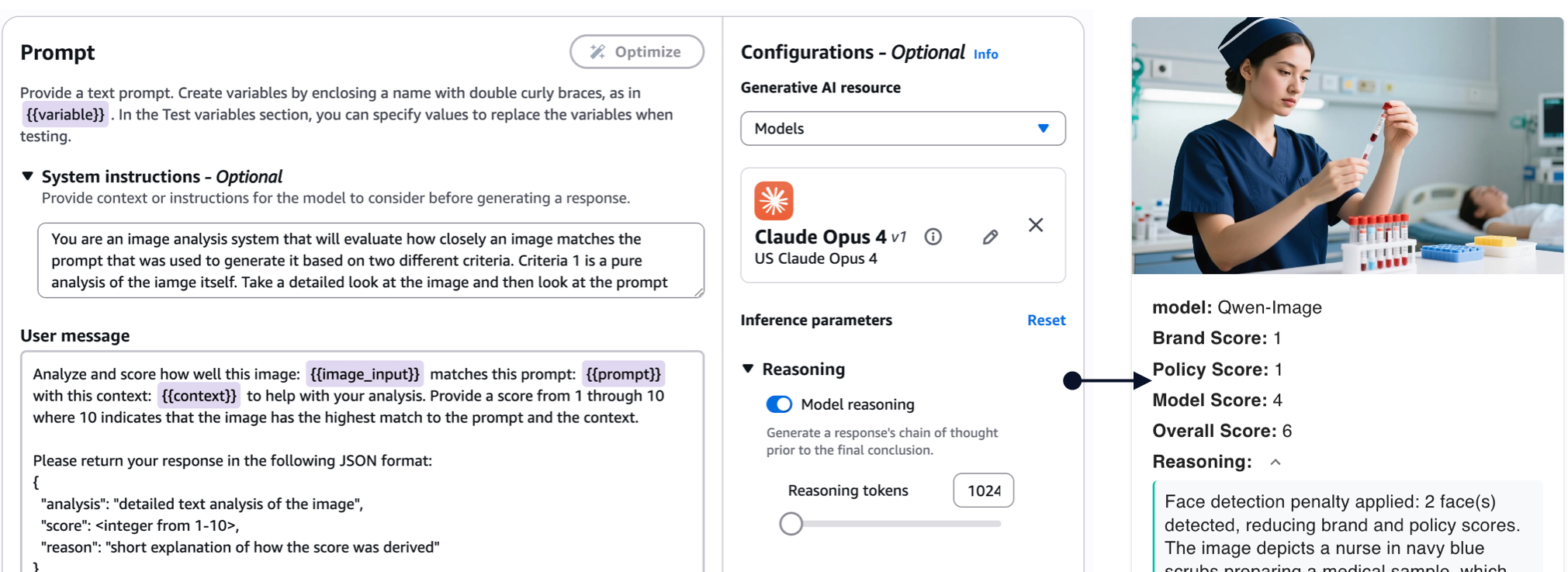
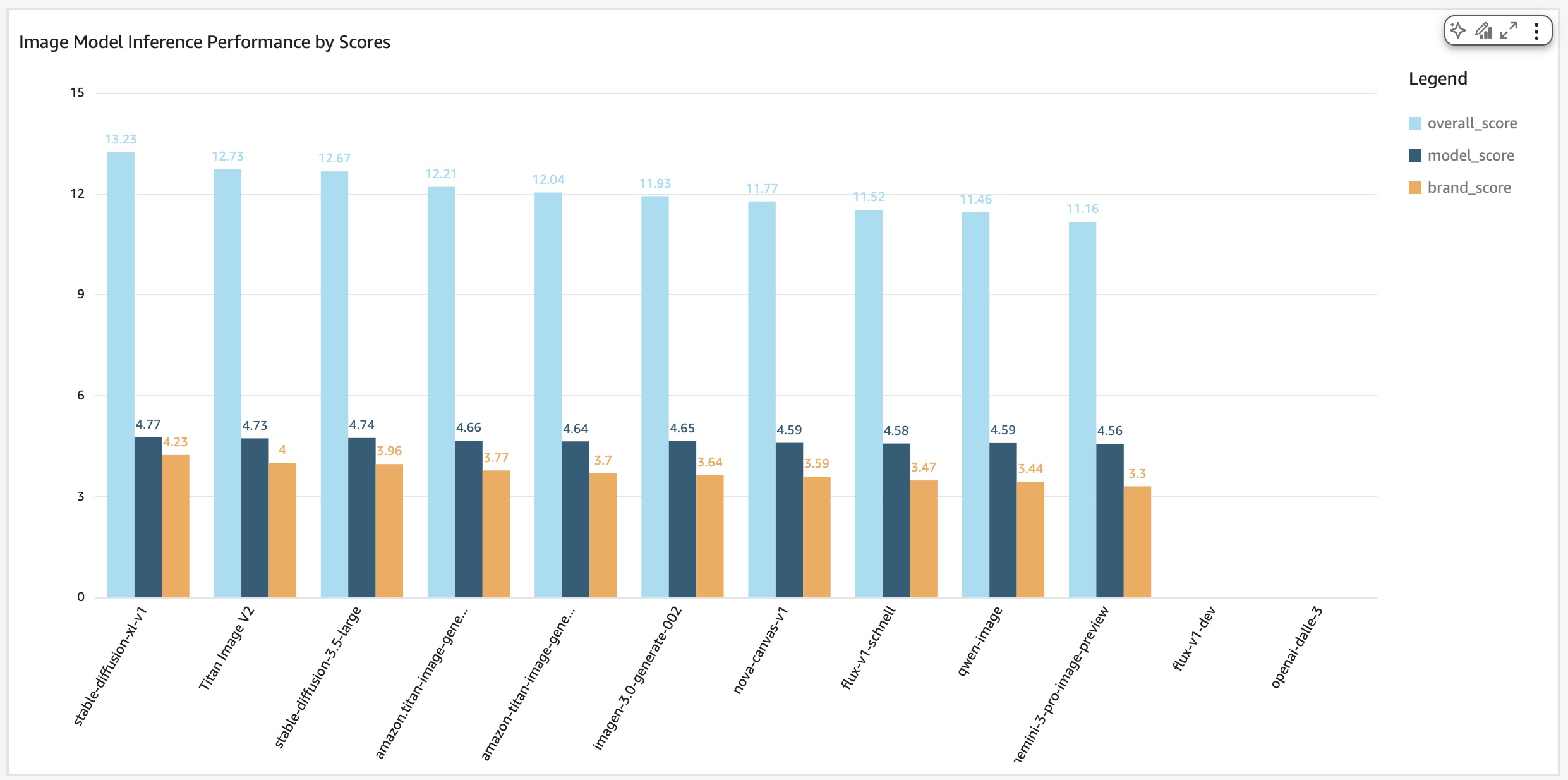
Each generated image is evaluated by an LLM using a managed prompt with quality, brand and policy guidelines from a knowledge base as context. The response includes scores for each criteria, an overall score and short reasoning summary to help end users determine appropriate images. These scores also help accelerate the human review.
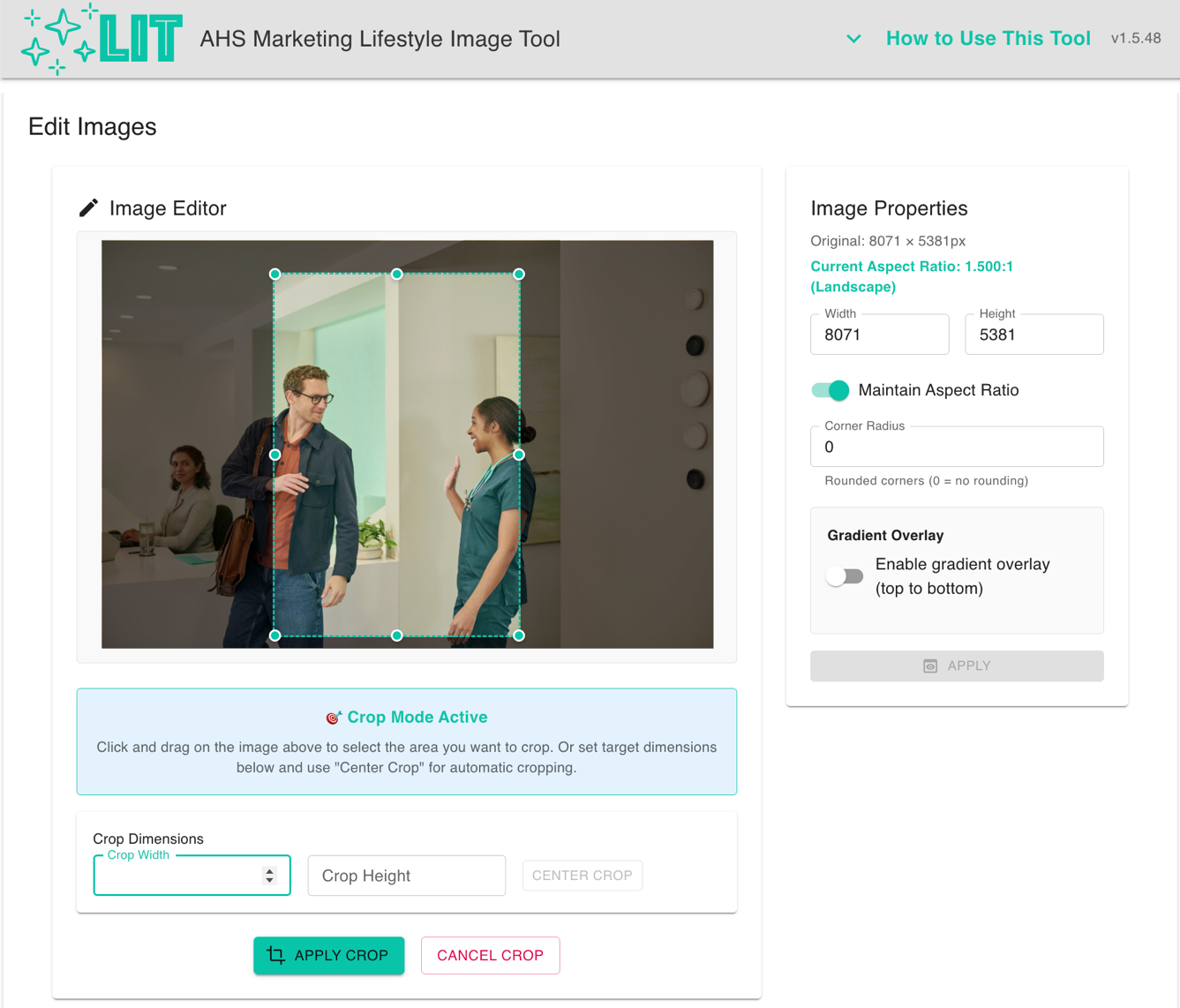
Some ad formats that are run on Amazon channels require specific image crops, rounded corners and gradient overlays. During ideation we determined that offering editing features within the application would reduce production time by up to four days.
While these edit features do not require AI, they resolved a pain point by making small design tasks easier for marketing managers without training.
Research and Development
Real-time image evaluation and scoring in the application was inspired and influenced by recent research. Specifically I leveraged the "LLM as Judge" concept to develop algorithms and workflows to derive evaluation scoring. I also took inspiration from a research presentation from Pierre Boyeau, where he discussed how to evaluate the performance of human-algorithm systems.
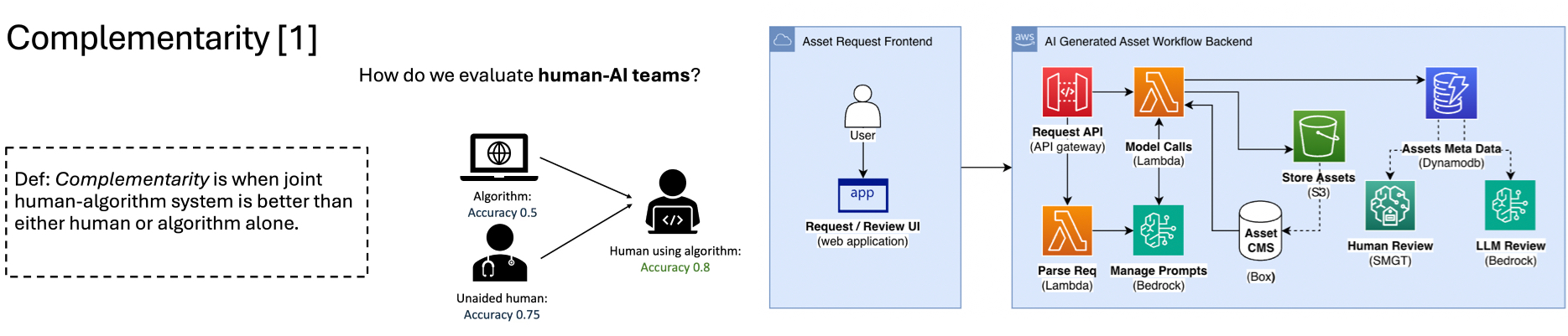
This work provides statistical evidence that a human-algorithm judgement system can be more accurate than human review alone. An additional part of the workflow not shown utilizes Amazon SageMaker Ground Truth to collect human evaluations on generated images.
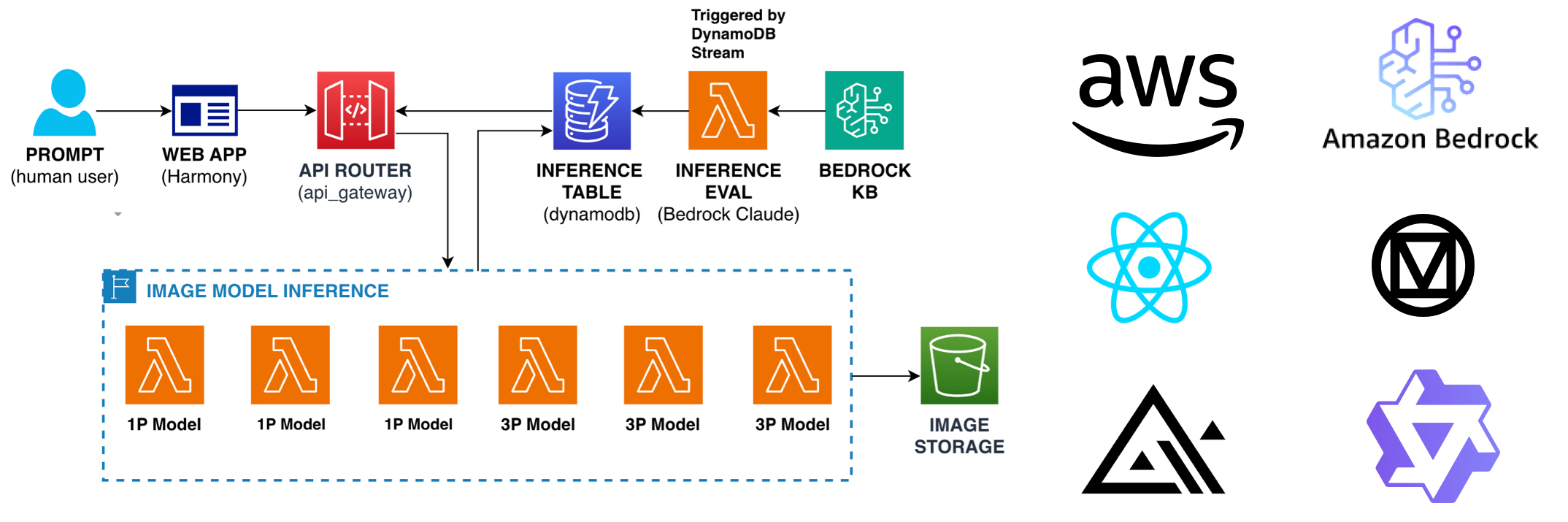
A high-level architectural diagram above shows an engineering pattern with an AWS lambda serverless function for each generative model. This pattern enables scalable, parallel processing with set and forget calls and front-end polling. The lambdas store images on S3 and write inference responses to a dynamoDB table that triggers the evaluations. The tech stack is React.JS for the front-end with Material 3 as the design system for the UI. APIs via AWS APIGateway connects the front-end to back-end which uses open-source models from Qwen and Flux as well as models on Amazon Bedrock.
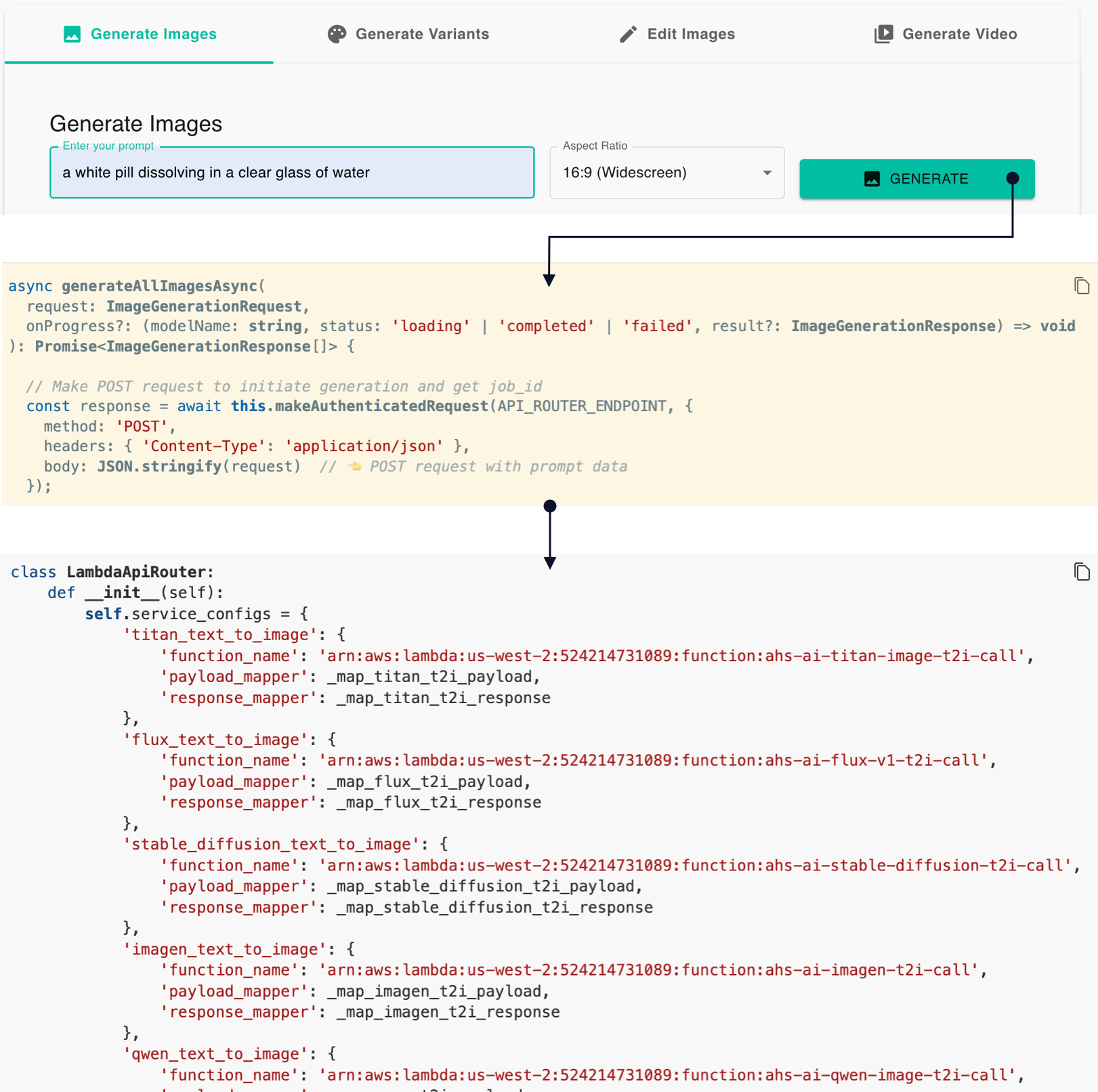
The real power of AI applications is how one or more structured prompts can be triggered at the click of a button. In the example below we trigger prompts that automatically generate a range of background scene variations. All the end-user has to do is upload an image, select drop-down menu items and generate without prompting.
AI Safeguards
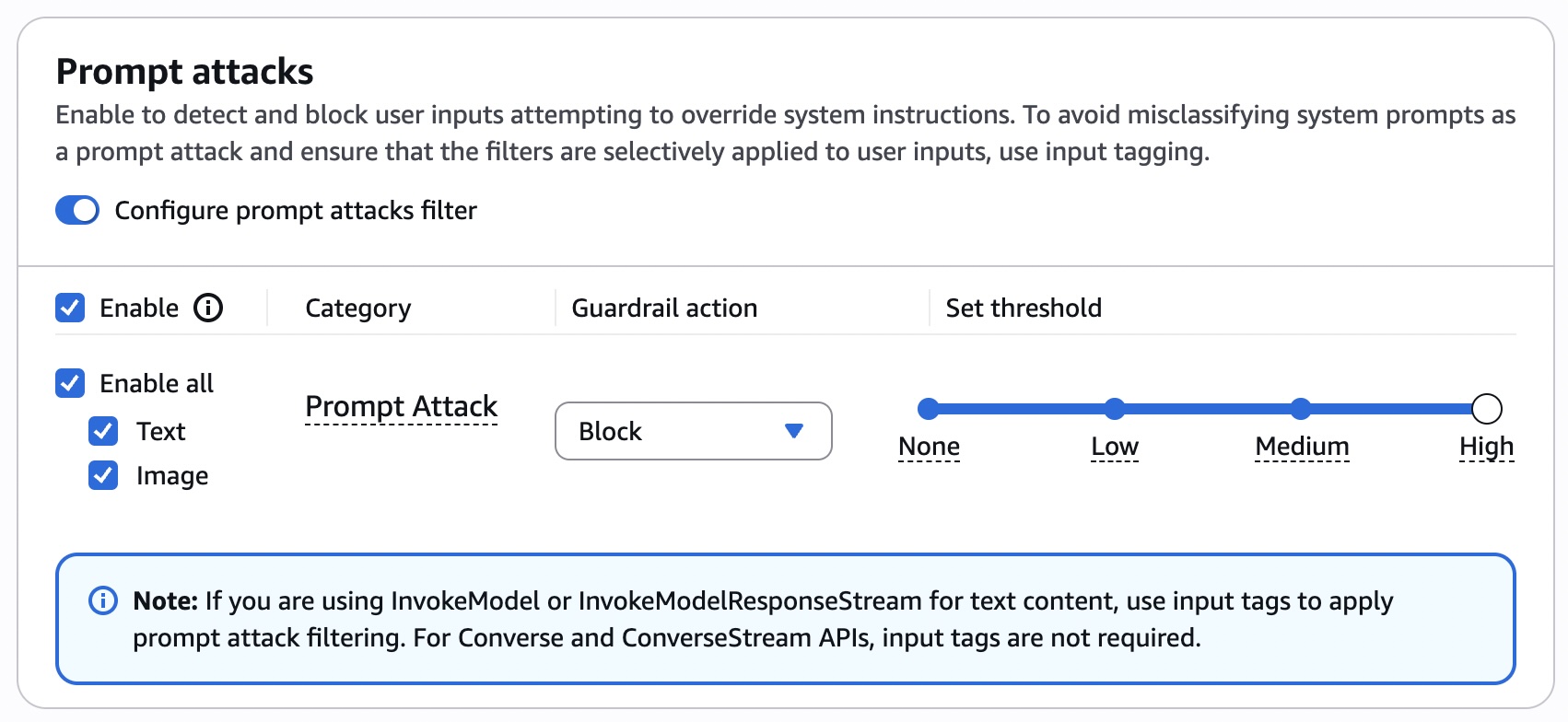
In addition to using aligned and guarded models, I implemented explicit guardrails on multimodal prompts and responses using Amazon Bedrock Guardrails. Examples of these guardrails included blocking prompts to generate images of specific medical conditions.
Software Documentation

Documented the architectural designs, key components, data schemas and changelogs leveraging AI assistants and deployment scripts.
Prototype and Results
Image Generation
The video below shows the application generating images from six different models based on one user prompt. As each image is generated an evaluation process on the image is triggered. This is represented by the scores. Where scores are pending the evaluation process hasn't completed yet.
Image In-painting
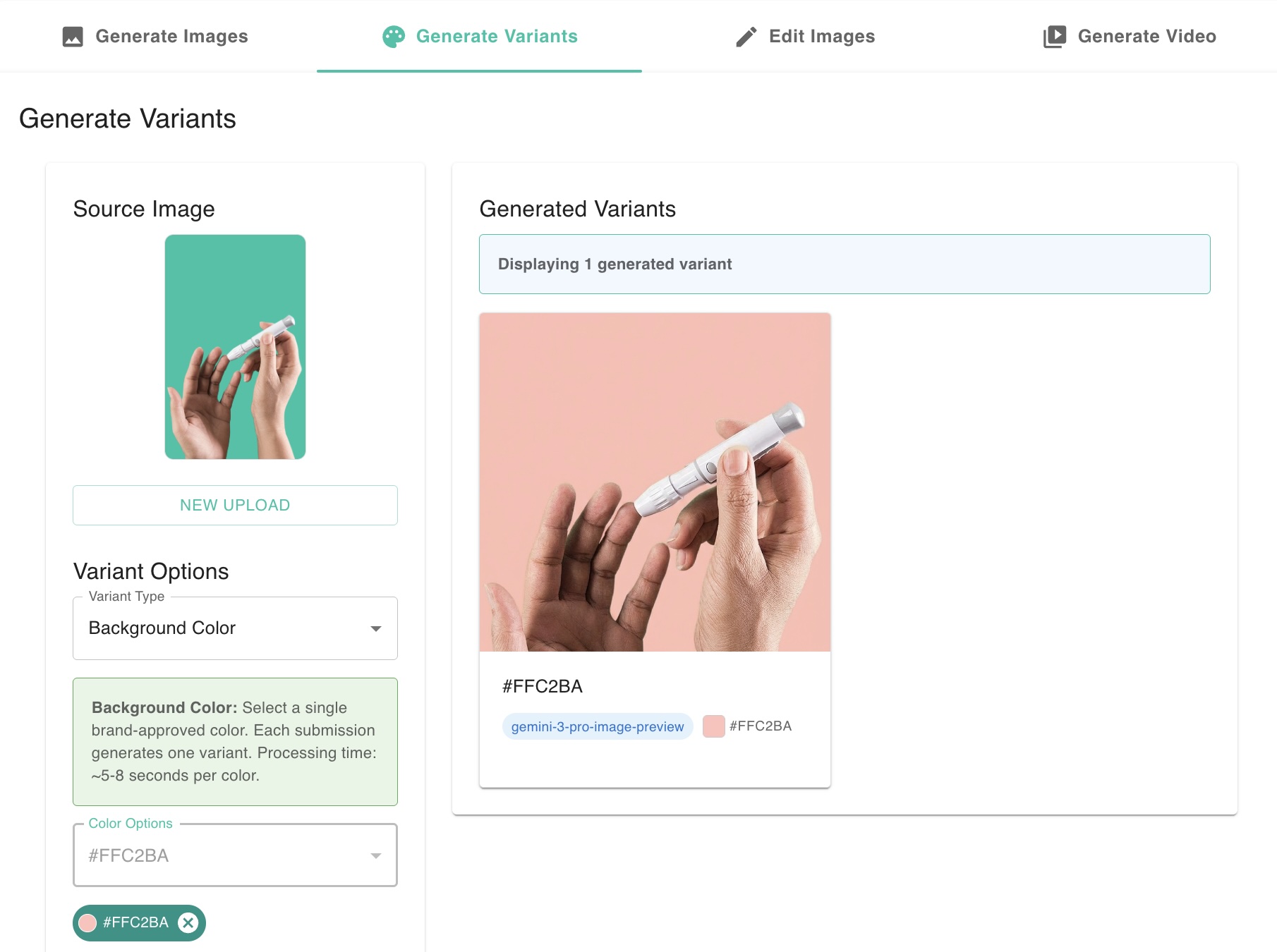
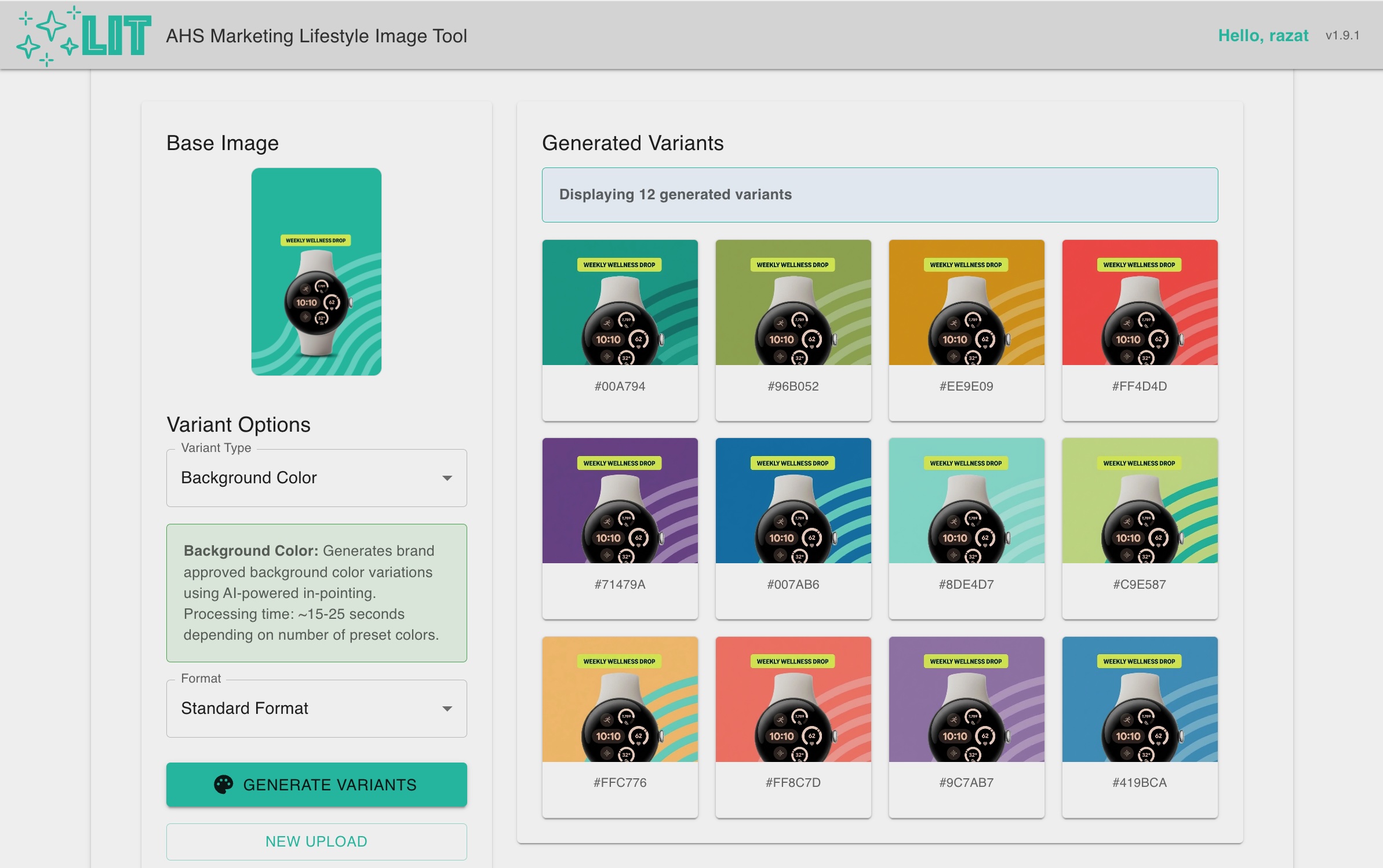
Using AI models to fill-in or replace a selected area inside an image. With LIT managed the image masking and managed multiple preset and optional user prompts in parallel for workflows like background color and scene replacement.
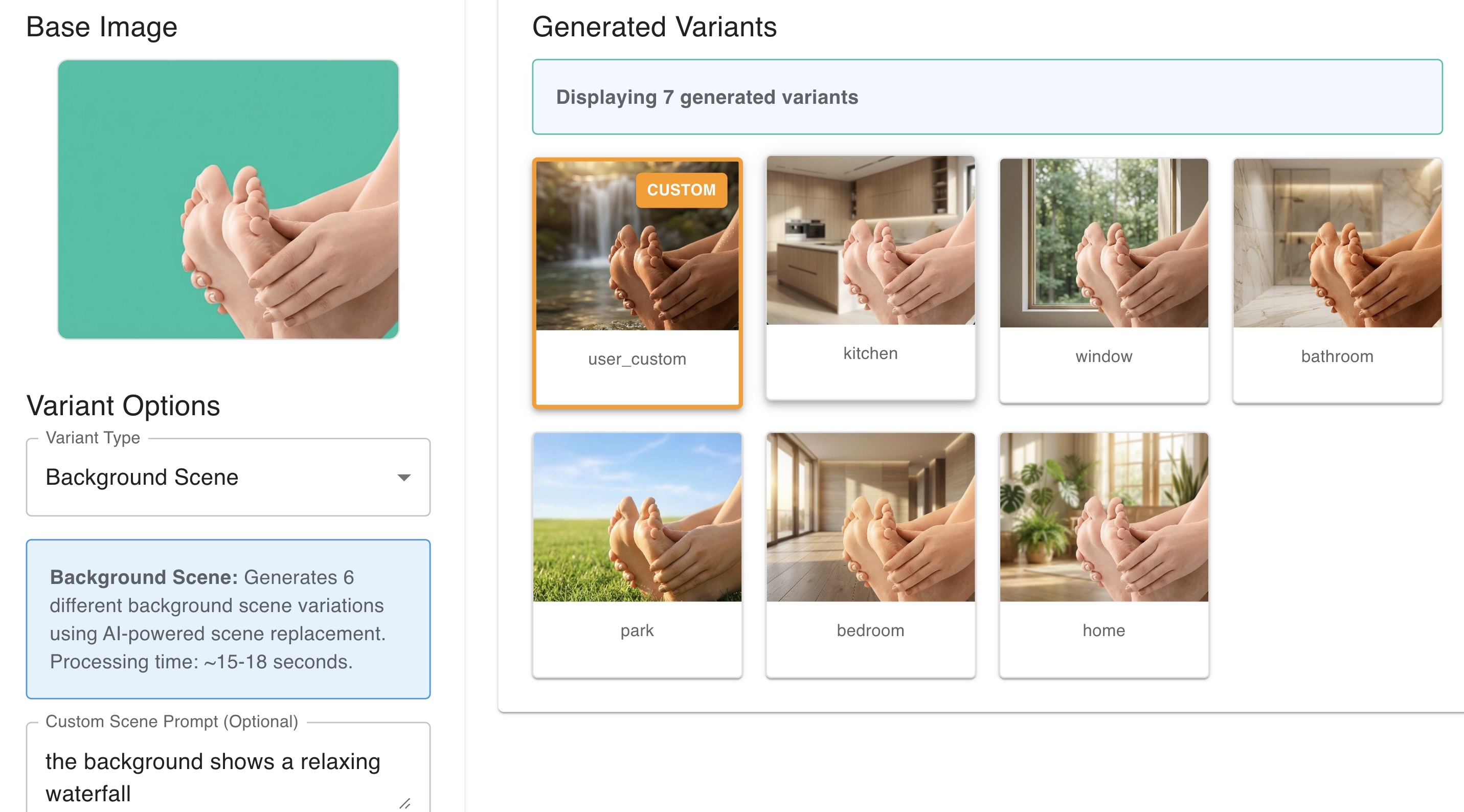
In the back-end additional structered prompts were used to ensure that important details of the source image such as ambient patterns and shapes or subtle shadows were preserved. There were also prompts to add realistic lighting and shading to the foreground images to match the lighting of the AI generated background images.

The video below shows the application generating new images with different background colors from a source image. The prompts to change the background to various hex values is abstracted from the user. All the user has to do is use the drop down and click the generate variants button.
Image Out-painting
Using AI models to extend an image beyond its original borders. AI generates new content to expand the canvas.
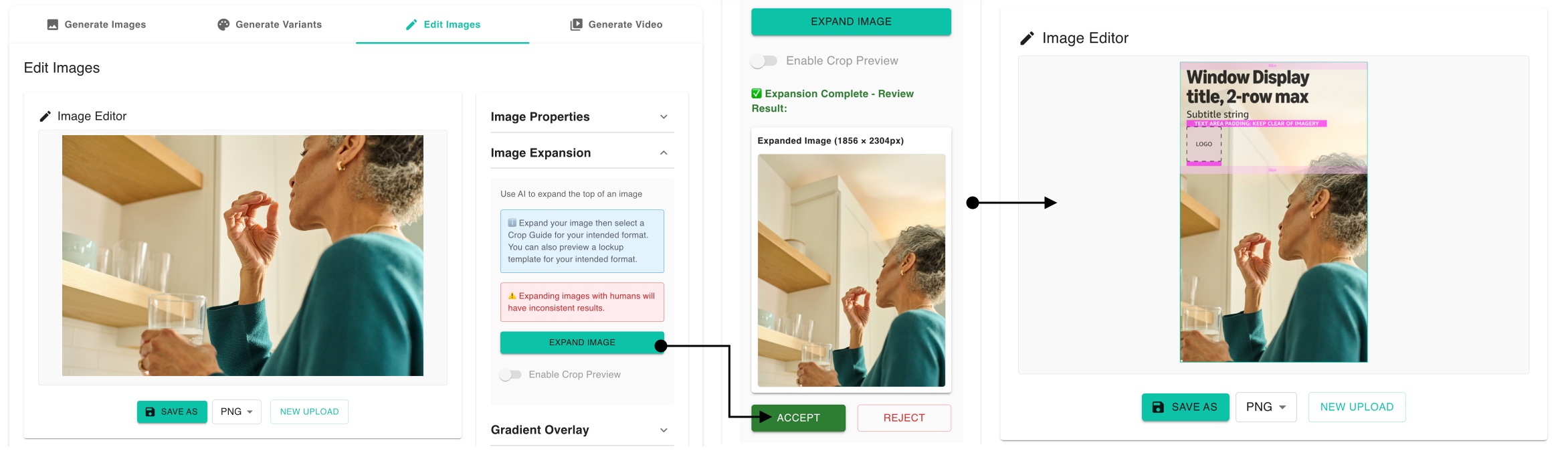
The LIT application enabled workflows to expand studio and stock photography by taking the detailed prompts required for out-painting and abstracting them to menu selection of marketing formats. Within the tool marketing lock-ups could be overlaid on the final images.
Interactive Canvas
Using an AI coding assistant I was able to quickly develop and prototype advanced interactive features days instead of weeks. The video below demonstrates the use of UI style overlays on AI generated content to assemble brand approved marketing creatives in one tool.
The interactive canvas and the overlay features were an important contribution to achieving Goal #3. The end-users of LIT did not have the access or the training to Figma, the design tool used by the creative team. By incorporating some of the design workflows normaly done in Figma we observed up to an 85% increase (14 days to 2) production speed.
Methodology
This project required rapid prototyping so I engineered the back-end and relied on an AI coding assistant for the front-end.
The cloud architecture was configured to be plug and play to swap different GenAI models in and out based on capability and availability. The engineering was solid enough to easily scale the prototype from five to fifty end-users.
With React.js and Material Design 3 my Cline coding assistant powered by Claude Sonnet 4.x was able to quickly build and test the UI based on my UX instructions.
My AI managment methodology was to trust but verify, with the assistant writing extensive tests and documentation.
As a former UX designer I enjoyed establishing a workflow where low fidelity wireframes were quickly mocked up to act as the starting points for user interface development prompts. This process could definitely be refined in the future but worked seamlessly because of my upfronts decisions on the design system and application goals.
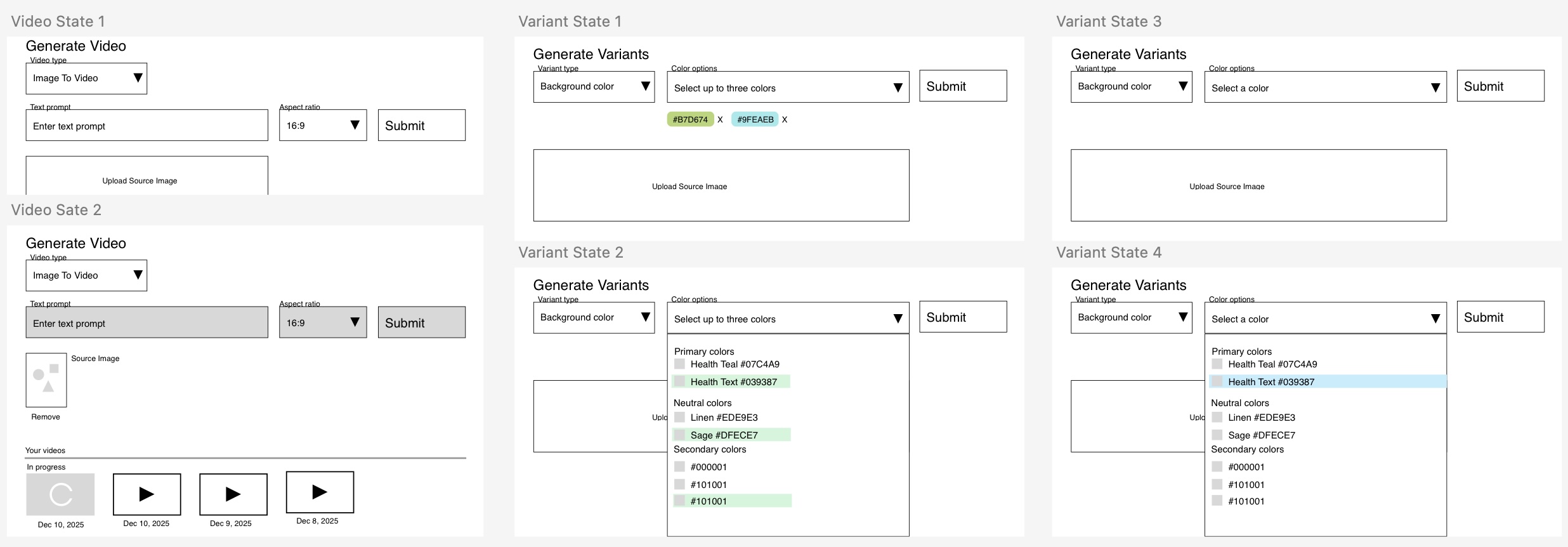
Examples like the lofi wireframes above when added to specifc prompts resulted in zero shot UI implementations. This helped build a highly productive workflow for rapid prototyping.
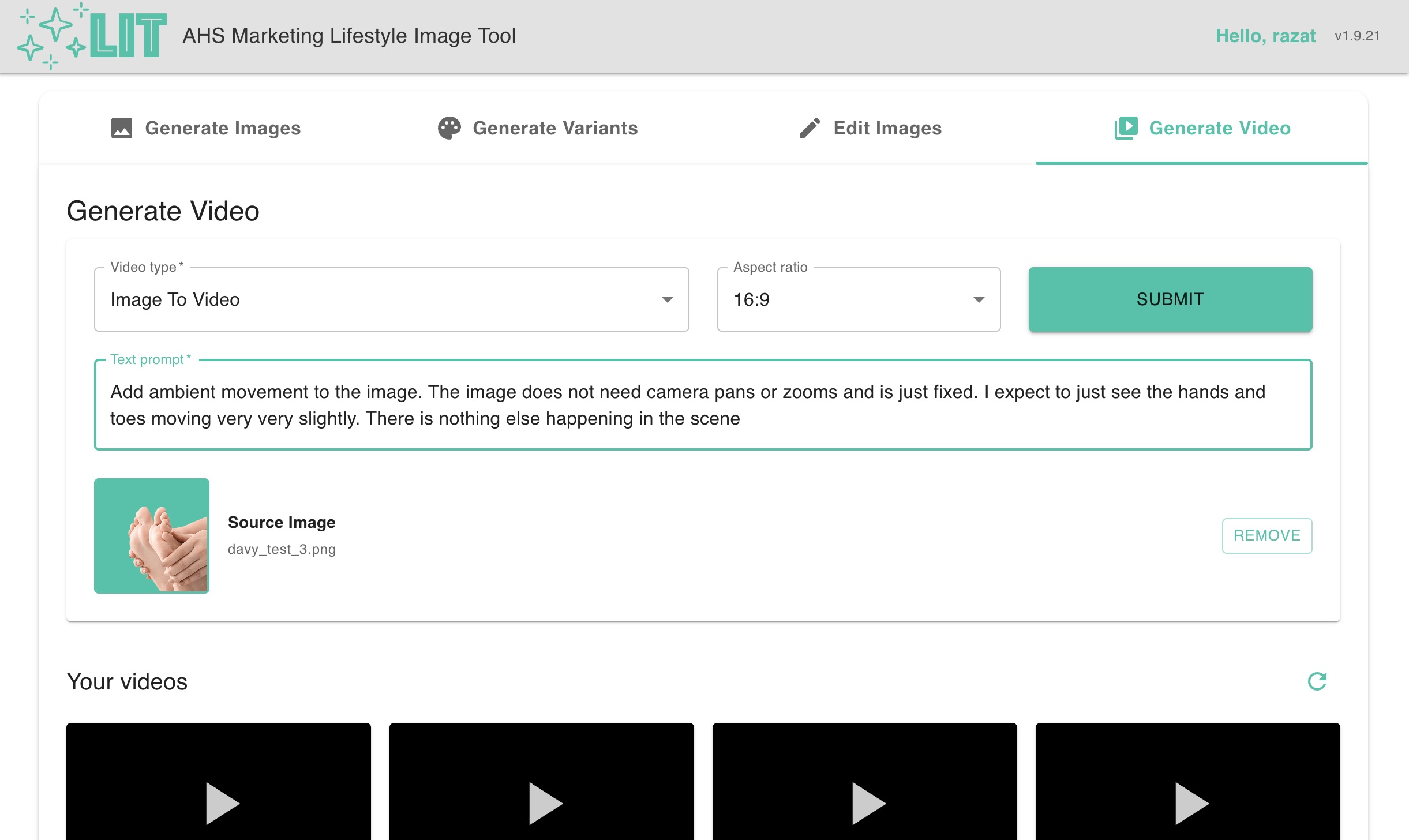
The user interface for image to video generation from a prompt and lofi wireframes
The user interface for generation of image variants from a prompt and lofi wireframes
Technical Challenges
Creating short video from a static image was pretty high on the stakeholder wishlist. The availability and scalability of high-quality and approved models was the only technical challenge that went unsolved by the time the prototype launched. As a mitigation we planned a small data collection to fine-tune with an internal model.


In-painting models that matched our exact hex color values were often not good at preserving shadows. The models that were the best at masking may not have been the best at preserving ambient details, color patterns and shadows. Some models didn't understand hex values in prompts for background color replacement. The solve this I initially used multi-model workflows and ensemble approaches to leveger the strengths of some models to mitigtate the weaknesses of others.
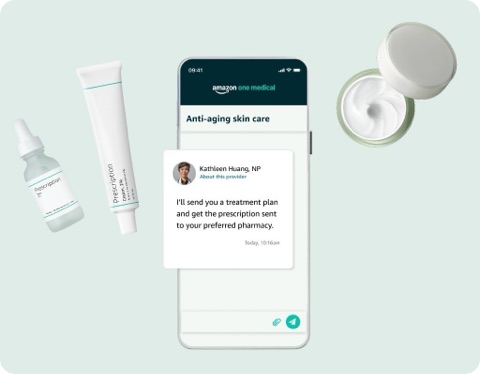
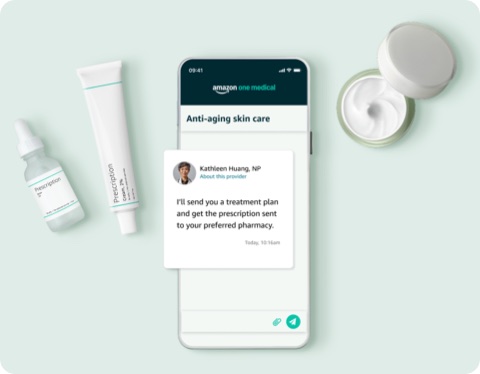
Additionally I used highly structured and conditional prompts in the background to ensure that end-users would see one or more successfully generated images without needing to know how to prompt.
Learnings
One model isn't enough - You need two or more for creative tasks
By far the most valuable learning and biggest takeaway was understanding how to leverage the exponential power of AI image generation to enable decision flexibility. In design use cases for the marketing domain, creative choice is intrinsic to high quality production. This application both enabled creative decision making and codified it was performance metrics.
-
AI generated images can be objectively rated and reviewed
You never want to completely remove human judgment, however if your use case calls for the generation of thousands of creative assets, then automatic review is required. I learned how to enable automated reviews, measure and compare model performance, and how to build image analysis systems to effectively enforce creative guidelines.
-
Latency matters in AI applications - Parallelization and polling patterns help accomplish this
-
Human end-users appreciate surfacing the context and reasoning behind generative outputs, especially for creative tasks
-
Patience pays off - Model performance improves so fast that this has to be a factor in planning
–